Introduction
Back in February of this year, I packed up my comfortable Canadian life in Calgary, Alberta and moved to Barcelona, Spain to obtain an education in the Mediterranean lifestyle, European cultures, un poco español and some Artificial Intelligence. Having never moved to a new country on my own before, I was overwhelmed by the diverse languages and cultures of Barcelona, and for the first time, I felt truely lonely. With so many cool things to explore and experience in my new city, it took longer than I anticipated to find a group of people to share those experiences with. I realized that making new friends in your mid-twenties isn't quite the same as it was back on the playground, so I began to break out of my comfort zone by using meetup.com to attend events I found interesting. It's been a fantastic application for finding new friends and...
Continue Reading...
Introduction
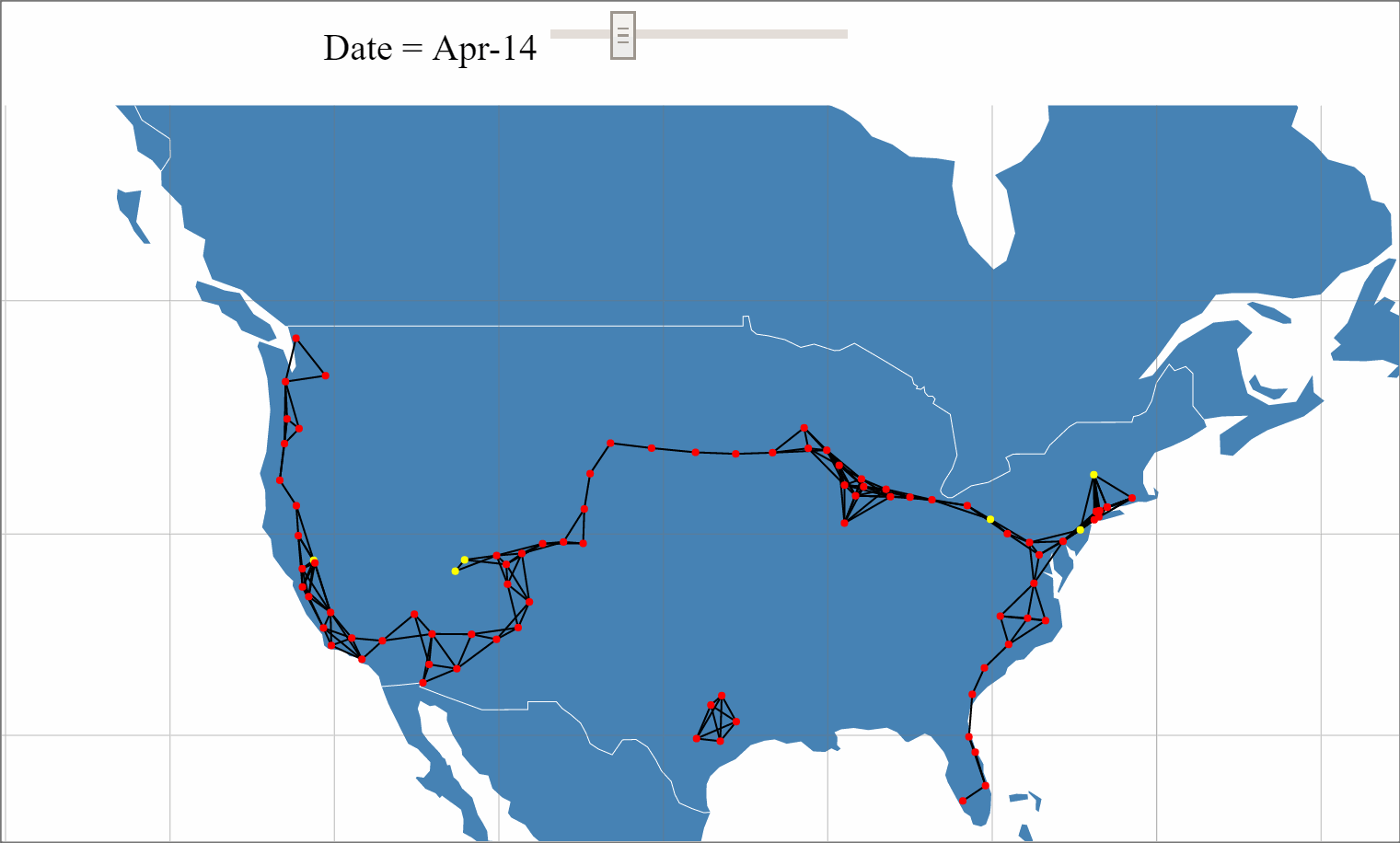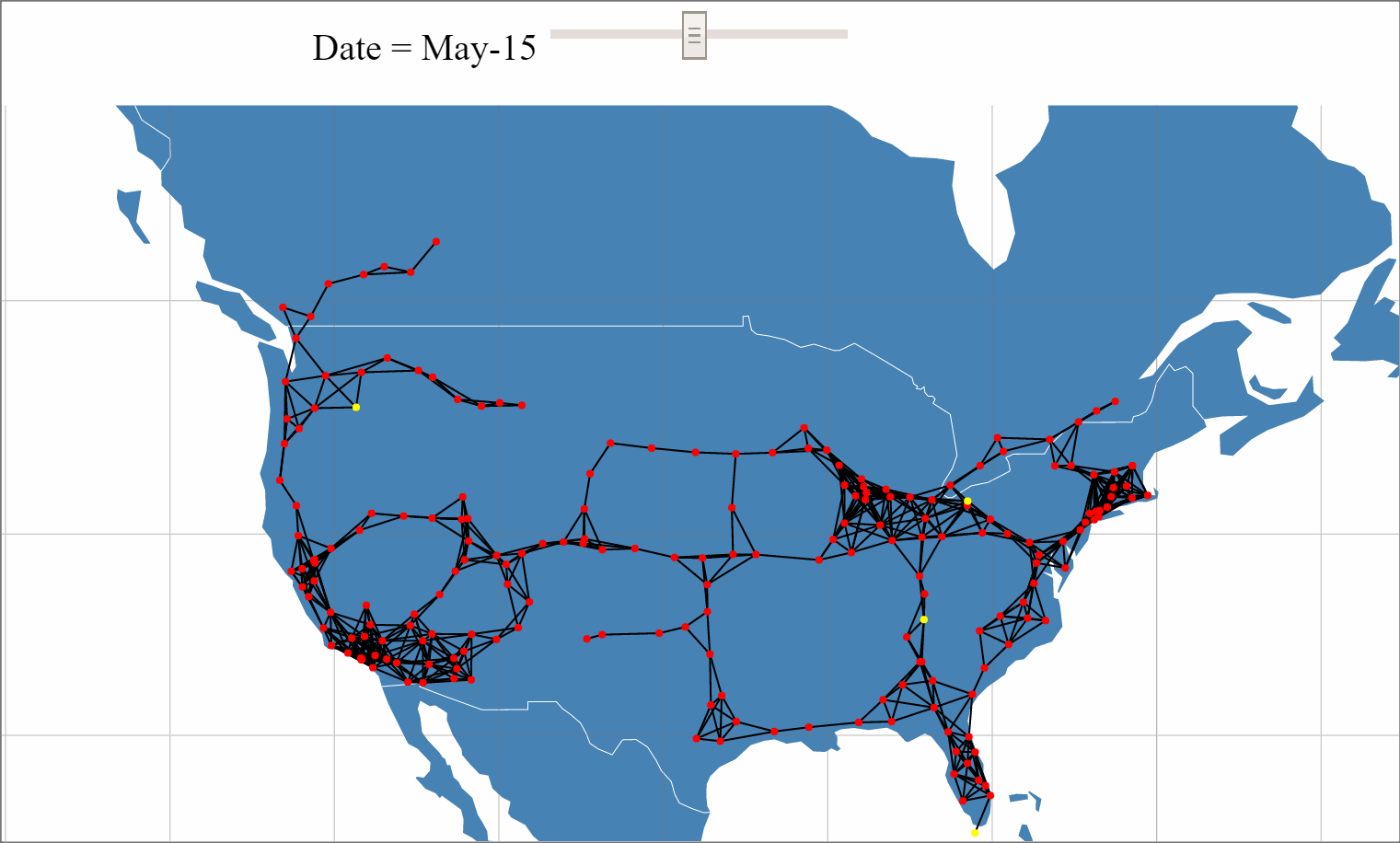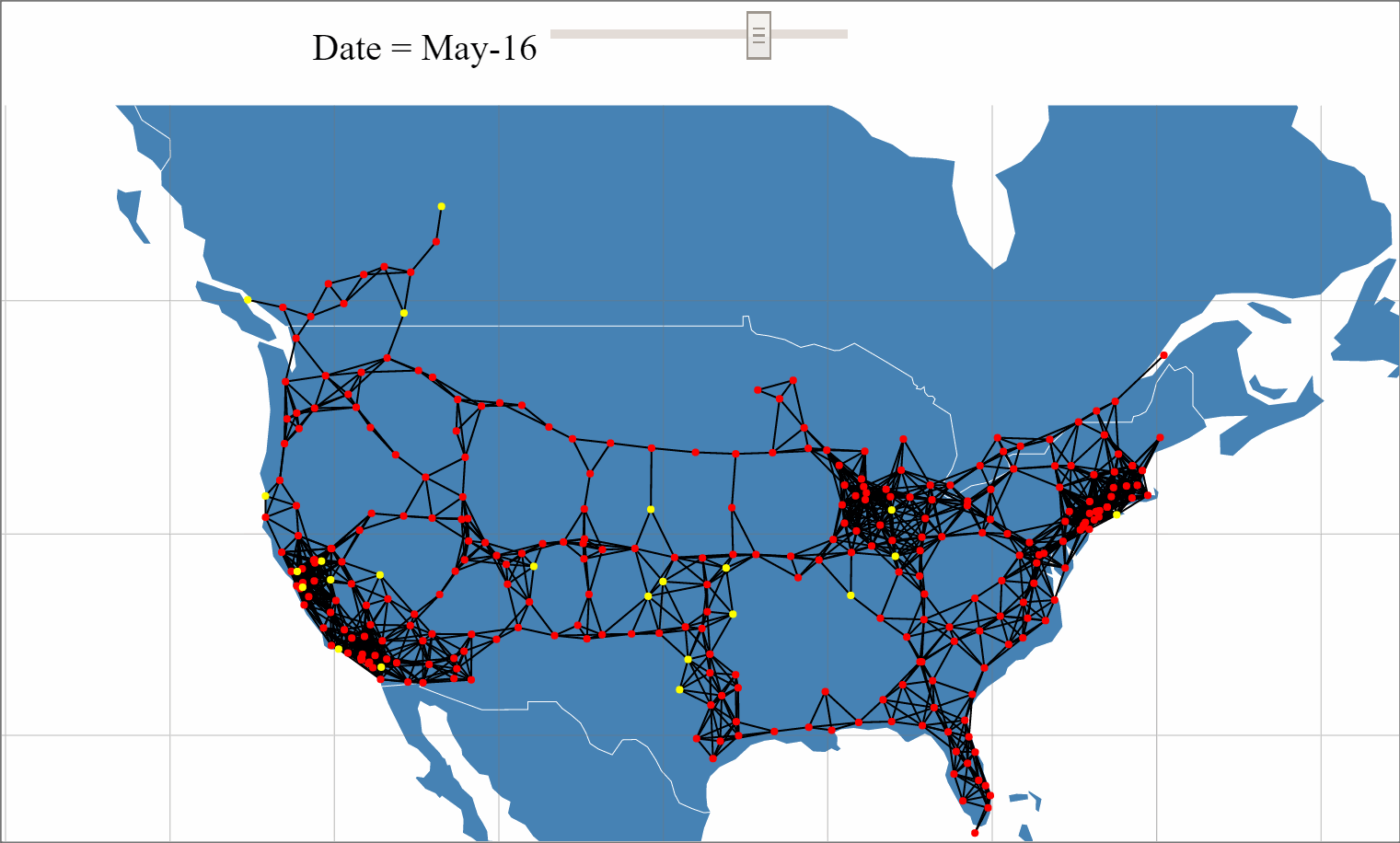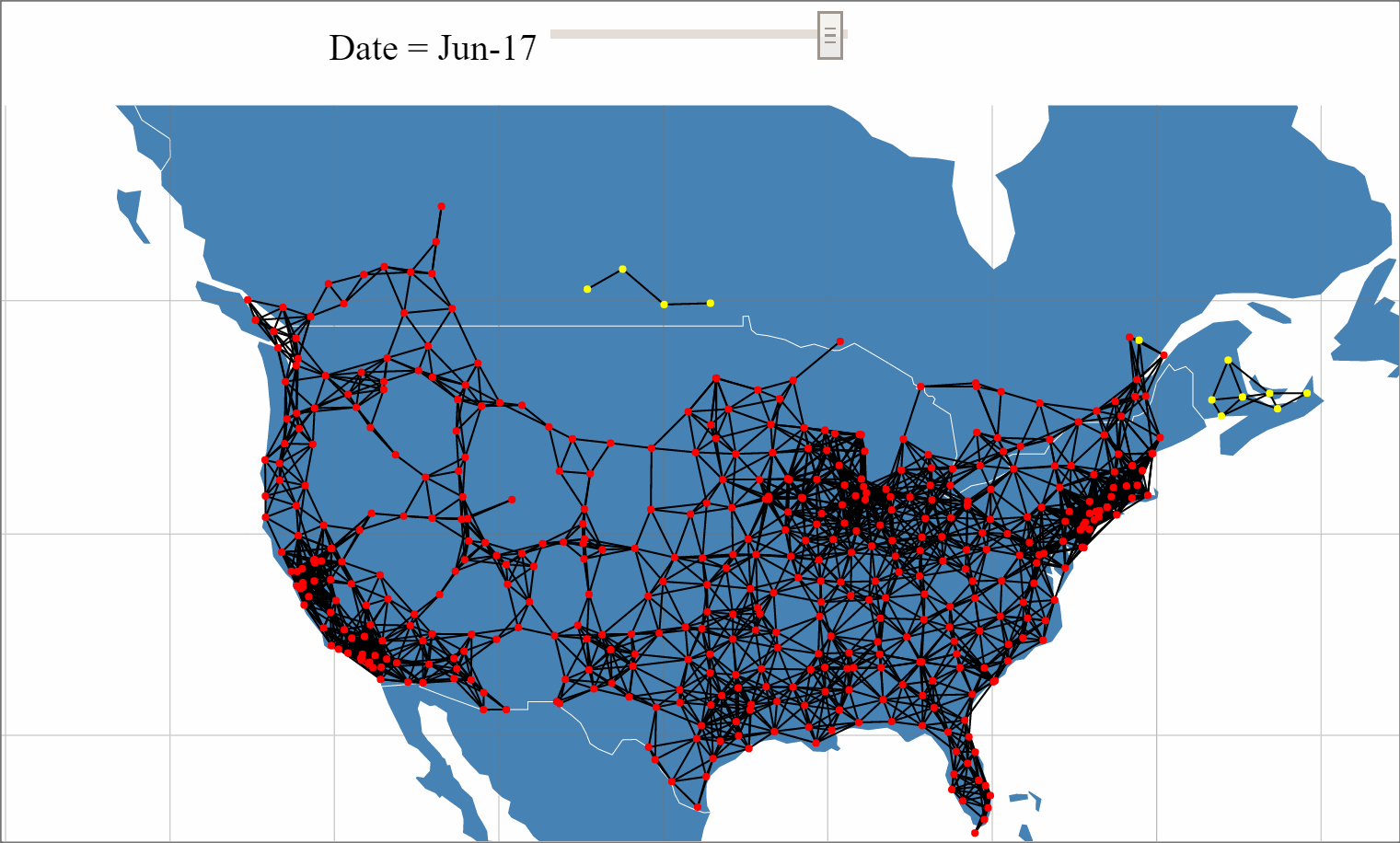
With the recent unveiling of Tesla's Model 3 and pre-orders approaching 400,000, the internet has been buzzing with Tesla discussions and analysis. One of Tesla's key differentiators from other mass market Electric Vehicals (EVs) is its Super Charger (SC) network that provides 170 miles of range in 30 minutes source. With Elon Musk stating plans to double the size of the SC network by the end of 2017, a large amount of planning, resources and investment are being allocated to this network expansion.
An analysis to build a predictive mode for Tesla's Supercharger network expansion was performed using beaker notebooks.
The full analysis can be viewed here.
The interactive network data visualization can be viewed here
Visualization can be viewed here
Summary
This visualization attempts to encode the growth in size and scope of the scientific boundary for multiple disciplines by using the count of published scientific papers to the Arxiv pre-publishing website as a proxy for the "size" of a given scientific boundary. Meta data is collected using Arxiv's API. The titles of each paper in a given discipline and for a given year are passed into a "Bag of Words" categorization model that sorts each paper based on its abstract into a category, or defines a new category if a new cluster in the model emerges as more paper titles are added as the years progress. Each new category that is created is "born" from a parent category, which is determined as being the existing category that is most-like the newly created category, based on the words in the labels of each...
Continue Reading...