Introduction
Google's Artificial Intelligence research group, DeepMind recently released a python API, pySC2 for the popular Real Time Strategy (RTS) computer game, StarCraftII. After successfully conquering the boardgame, Go, with their AlphaGo program, DeepMind has set their sights on the next big challenge for AI systems in attempting to train these systems to learn how to compete with world champions in the increadibly complex world of StarCraft. In this post, we use the pySC2 API to collect gameplay data from replays of human played games with the aim of discoverying some macro elements of the game, such as the different technology progression trees players use. Ultimately, the hope is to build up some intuition on what data is availible from the pySC2 API and how it might be useful in building systems capable of playing the game, but that work will be outside the scope of...
Continue Reading...
Introduction
As part of a project course in my second semester, we were tasked with building a system of our chosing that encorporated or showcased any of the Computational Intelligence techniques we learned about in class. For our project, we decided to investigate the application of Recurrent Neural Networks to the task of building a Subreddit recommender system for Reddit users. In this post, I outline some of the implementation details of the final system. A minimal webapp for the final model can be interacted with here, The final research paper for the project can be found here and my collaboraters on the project are Barbara Garza and Suren Oganesian. The github repo for the project can be found here with this jupyter notebook being here.
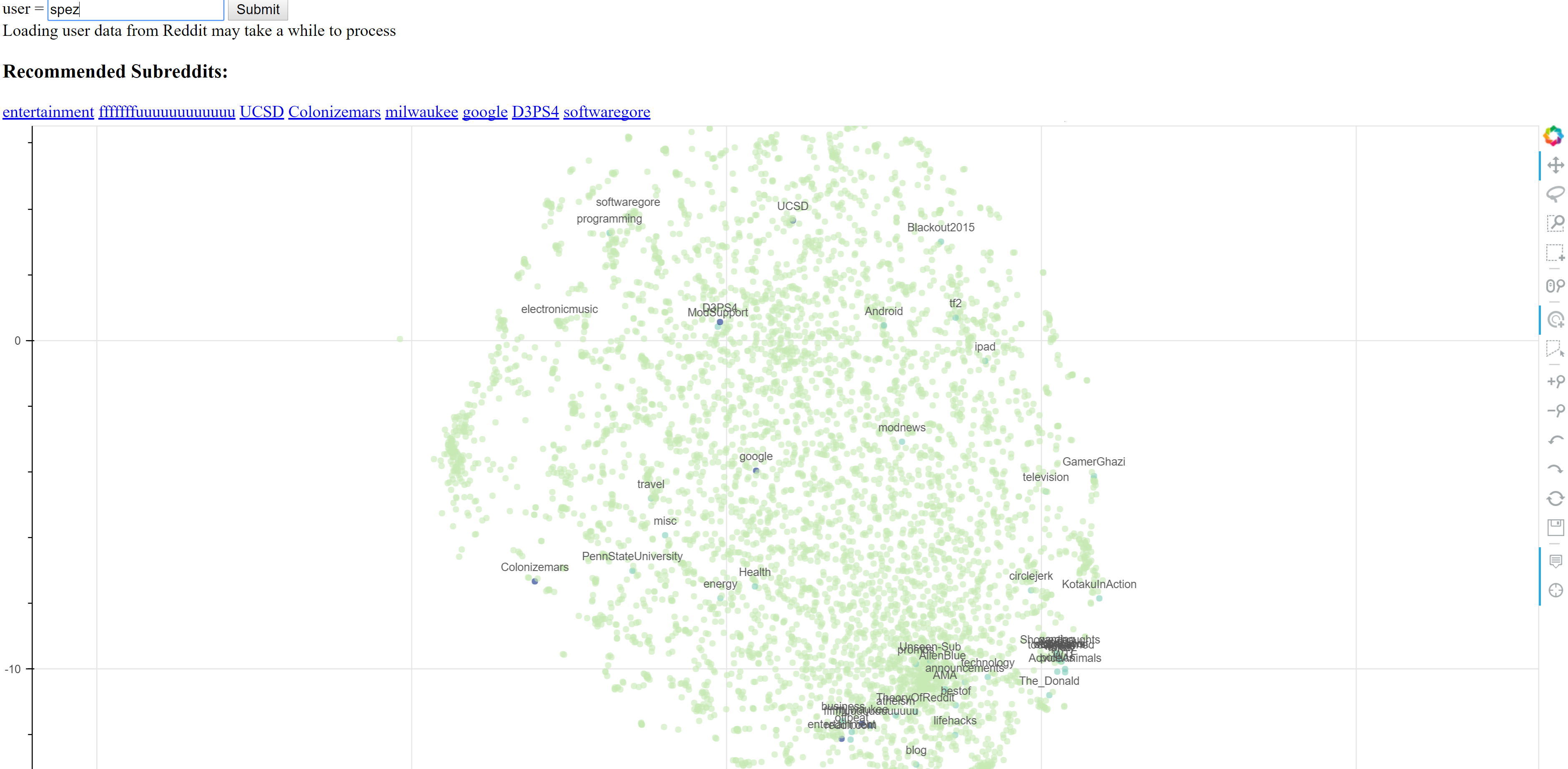
Model Hypothesis
The goal of the project is to utilize the sequence prediction power of RNN's to...
Continue Reading...
MAI-IML Exercise 4: Adaboost from Scratch and Predicting Customer Churn
Abstract
In this work, we develop a custom adaboost classifier compatible with the sklearn package and test it on a dataset from a telecommunication company requiring the correct classification of custumers likely to "churn", or quit their services, for use in developing investment plans to retain these high risk customers.
Adaboost from Scratch
Defined below is an sklearn compatable estimator utilizing the adaboost algorithm to perform binary classification. The input parameters for this estimator is the number of weak learners (which are decision tree stubs on a single, randomly selected feature) to train and aggregate to produce the final classifier. An optional weight distribution can also be passed to the classifier, which defaults to uniform if not set. This custom estimator will later be utilized to develop a classifier capable of predicting customer churn from labelled customer data.
Continue Reading...
Introduction
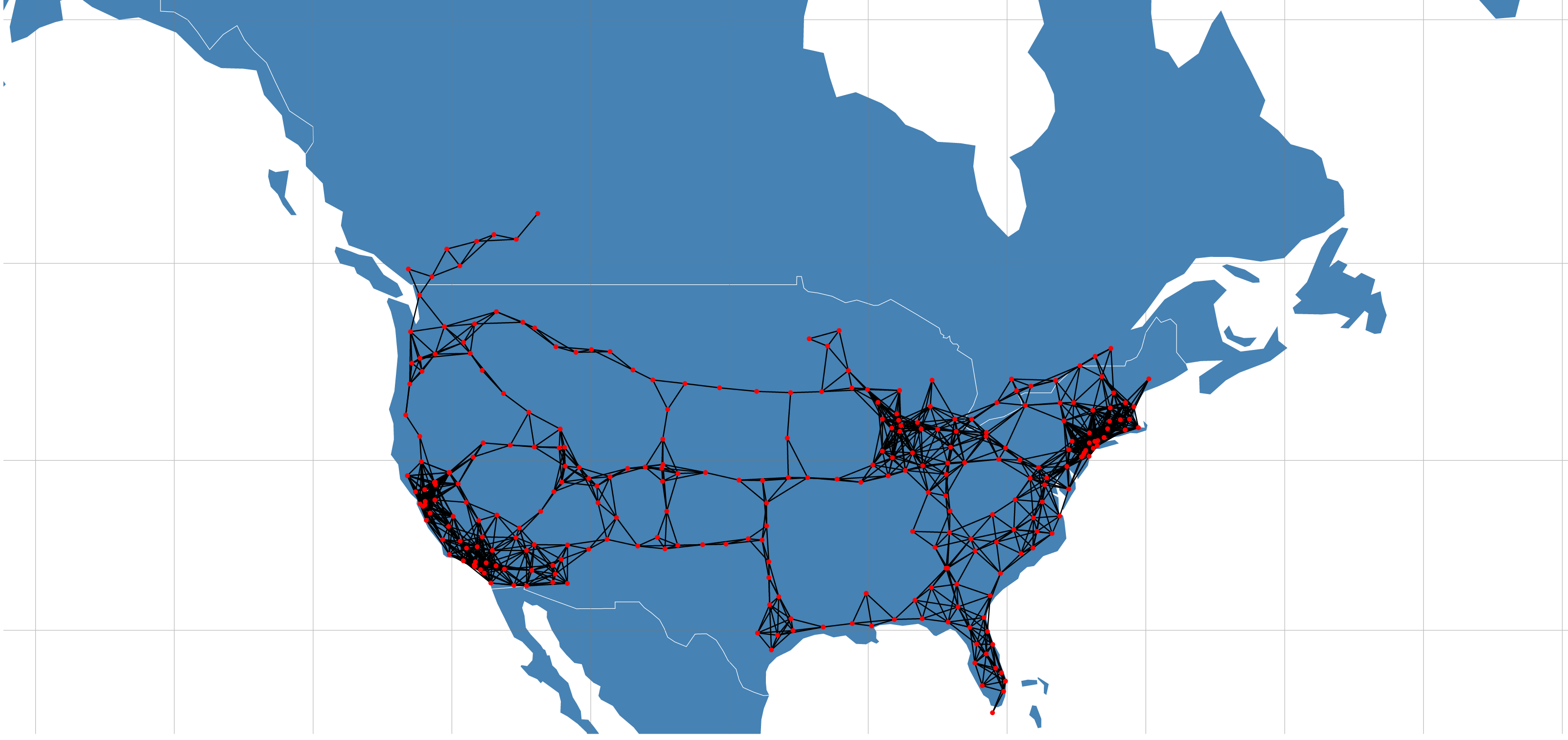
With the recent unveiling of Tesla's Model 3 and pre-orders approaching 400,000, the internet has been buzzing with Tesla discussions and analysis. One of Tesla's key differentiators from other mass market Electric Vehicals (EVs) is its Super Charger (SC) network that provides 170 miles of range in 30 minutes source. With Elon Musk stating plans to double the size of the SC network by the end of 2017, a large amount of planning, resources and investment are being allocated to this network expansion.
An analysis exploring Tesla's Supercharger network was performed using beaker notebooks and is currently the top rated notebook published on the platform.
The full analysis can be viewed here.
Visualization can be viewed here
Summary
This visualization attempts to encode the growth in size and scope of the scientific boundary for multiple disciplines by using the count of published scientific papers to the Arxiv pre-publishing website as a proxy for the "size" of a given scientific boundary. Meta data is collected using Arxiv's API. The titles of each paper in a given discipline and for a given year are passed into a "Bag of Words" categorization model that sorts each paper based on its abstract into a category, or defines a new category if a new cluster in the model emerges as more paper titles are added as the years progress. Each new category that is created is "born" from a parent category, which is determined as being the existing category that is most-like the newly created category, based on the words in the labels of each...
Continue Reading...
Introduction
The Daily Fantasy Sports (DFS) industry has exploded in popularity in recent years, largely due to the exponential growth of users playing on industry titans such as Fanduel and DraftKings. These platforms allow users to gamble real money by selecting a set of players known as a roster from a sport, with rules constraining the total salary and specific player position types required for a selected roster.Each player in the roster can accumulate points based on their performance in the sport in the upcoming game that day.The user then enters this roster into contests against other users who have also entered their rosters, with the aim of selecting the roster that accumulates the most points based on the competitions set rule for point accumulation. The user or subset of users with the top accumulated points at the end of the competition win the pot of money entered...
Continue Reading...
Data Munging and Analyzing Barcelona OSM Data
The XML data for the city boundary of Barcelona was downloaded from OSM to clean and transform into a json encodable structure to allow loading into MongoDB, providing storage and artbitrary querying to enable further data analysis of the Barcelona OSM dataset. I chose the Barcelona dataset because I just recently spent a few weeks there and noticed some pretty cool urban planning features of the city (ie. Avinguda Diagonal) that could be cool to explore further.
Inspired by the "Diagonality" of Barcelona streets and to give the scope of the project a little more focus, I will be attempting to analyze the Barcelona OSM data and see if I can generate a measure for the "degree of diagionality" for Barcelona and possibly compare this measure with other cities. Not knowing ahead of time the difficulty of this, I may eventually have to...
Continue Reading...